
캐시란?
캐시는 일종의 메모리로, CPU에서 메모리에 접근하는데 드는 시간을 줄이기 위해 만들어졌다.
캐시를 사용하는 다양한 방법이 연구되어 왔으며 이 글에서는 direct mapped cache와 set-associative cache를 알아볼 것이다
아래의 글을 읽기 앞서, 캐시와 메모리의 차이점에 대해 조금 알아보자
메모리 VS 캐시
DRAM vs SRAM
하드웨어적으로 SRAM이 DRAM보다 더 빠르기 때문에 캐시는 SRAM, 메모리는 DRAM을 사용한다.
여기서 이 글을 읽으시는 분들은 메모리를 모두 캐시처럼 SRAM으로 대체하면 안될까? 라는 생각이 들것이다.
하지만 SRAM이 더 비싸서.. 그렇게는 할 수 없다.
.
Address 단위 vs Block 단위
메모리는 byte단위로 주소를 매핑한다. 반면에 캐시는 빠르고 많이 데이터를 올려놓기 위해서 여러개의 byte가 뭉친 block단위로 주소를 매핑한다.
Direct Mapped Cache
캐시에서 사용하는 주소는 다음과 같이 나누어져 있다.

Index
index는 캐시라인(Block)의 위치를 의미한다.
4비트 기준으로 0000로 되어있으면 0번째 라인을 가리킨다.
Tag
index만 있다면 한 캐시 주소에 여러 메모리 주소가 매핑되는 문제가 생긴다.
그래서 tag 값이 필요하다.
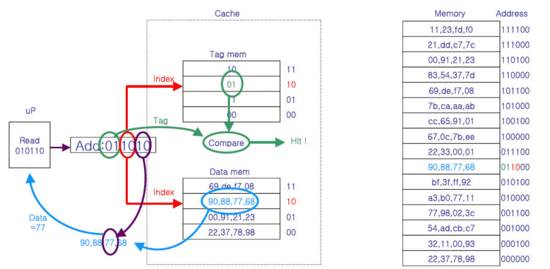
예를들어 위의 011000에 있는 값을 캐시에 올리고 001000에 있는 값을 찾는다고 해보자,
그러면 index가 10로 같아서 완전히 다른 값을 찾아줄 것이다.
그래서 tag를 한번 확인한다. 올라와 있는 값인 01과 찾는 값인 00가 달라서 miss 판정이 난다.
tag가 같을때를 Hit, 다를때를 Miss라고 한다.
Byte Offset
메모리나 캐시는 데이터를 word 단위로 처리하기 때문에 byte offset이 필요하다. (필요한 데이터가 1byte라고 해도 word로 읽는다)
Set Assoicative Cache
direct mapping 방식은 miss확률이 잦다.
그래서 cache의 block을 여러 블럭씩 묶은 Set을 추가한 방식이다.

이렇게 하면 하나의 index에 넣을 수 있는 값들이 많아지면서 miss를 줄일 수 있다.
하지만 set안의 block을 모두 봐야 하기 때문에 좀 더 시간이 걸린다.
'프로그래밍 > 기타' 카테고리의 다른 글
| [kubernetes] Error: unknown flag: --image (0) | 2022.08.08 |
|---|---|
| [pgAdmin] Utility file not found. Please correct the Binary Path in the Preferences dialog 오류 (0) | 2022.08.04 |
| 밀러-라빈 소수 판정법의 검사 반복 횟수는 얼마나 해야할까? (0) | 2020.11.04 |
| [Pygame/오류] Pygame에서 응답없음 (1) | 2020.09.24 |
| [DB/오류] Exception has occurred: TypeError %d format: a number is required, not str (0) | 2020.09.21 |