
🤔 발단
이전 프로젝트(Book recommendation) 때부터 자동화된 테스트를 도입하고 싶었다.
그래서 이전에도 사용해본 적 있는 "Github Action"을 꼭 써보고 싶었는데, 이번에 여러 문제를 겪으며 적용해보았다.
💥 문제1 - wandb logger
우리는 지금 당장은 통합테스트를 수행할 것이다.
그리고 Github Action을 이용할 것이기 때문에 API KEY가 필요한 것은 배제해야 한다.
-> 그것이 이번 문제의 주인공인 wandb가 되겠다.
📝 @patch
모킹은 좋은 방법이 아니지만, 어쩔 수 없이 써야 할 때가 있기 마련이다.
파이썬은 그래서 @patch라는 모킹 데코레이터 함수를 제공해주고 있다.
@patch(패키지.함수) 와 같은 형태로 테스트 함수에 달아주면 된다.
아무튼 아래와 같이 test code를 작성했다.
main은 프로그램 시작점이고, wandb.init, wandb.login 등의 함수가 호출되면 아무일도 일어나지 않게 될것이다.
+ 추가로 pytorch lightning logger에서도 wandb를 사용하기 때문에 이것도 모킹을 해줘야 한다.
from unittest.mock import patch, Mock
from main import main
@patch('wandb.init')
@patch('wandb.login')
@patch('wandb.log')
@patch('wandb.finish')
@patch('wandb.save')
@patch("pytorch_lightning.loggers.wandb.Run", new=Mock)
@patch("pytorch_lightning.loggers.wandb.wandb")
def test_main(*args, **kwargs):
main()
📝 Github Action
그리고 이제 github action의 workflow에 관한 설정파일을 작성해야 한다.
그러기 전에 먼저 짚고 넘어가자.
우리 팀의 프로젝트는 아래와 같이 tabular, sequential, graph approach로 구분해 별개의 프로젝트를 담고 있다.
때문에 별개로 가상환경도 설치해줘야 한다. (우리팀은 conda로 관리중)
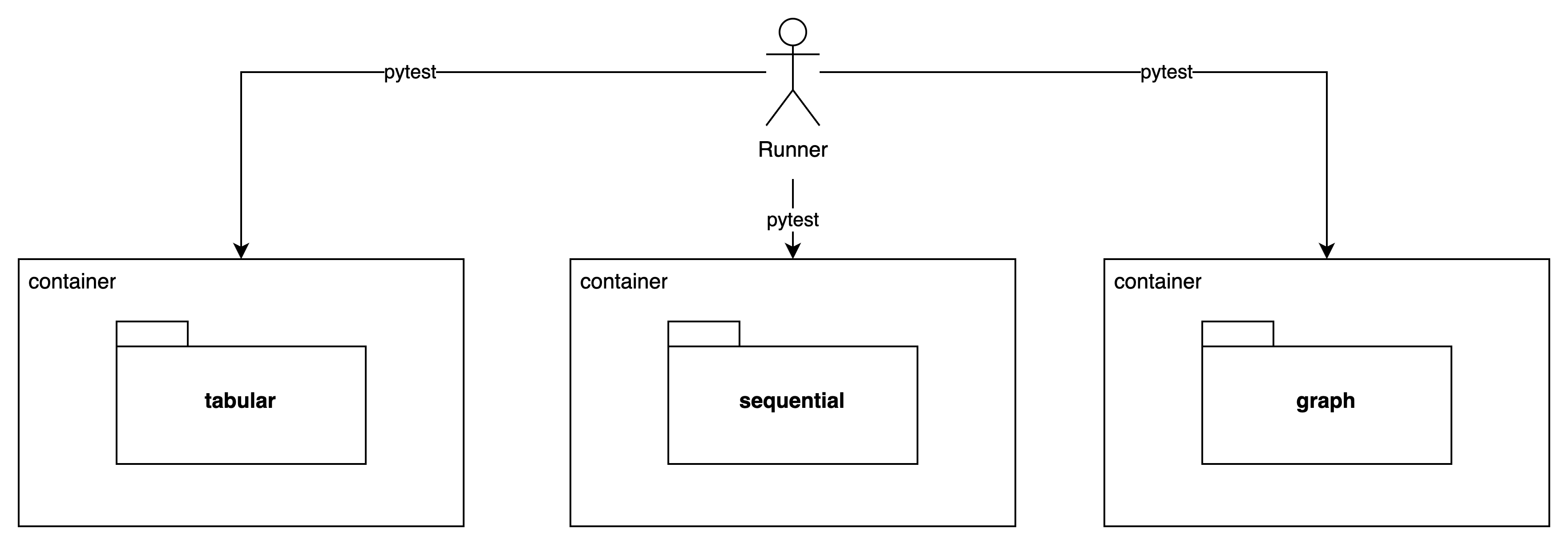
이러한 점은 job을 이용해 병렬로 각 어프로치 프로젝트의 테스트가 병렬로 돌아갈 수 있게 했다.
workflow yaml은 우리 팀원분이 아래와 같이 작성해 주셨다. (tabular는 아직 작성하지 않았다)
name: check bug before merge
on:
pull_request:
branches: [main]
jobs:
run_seq:
name: testing sequential approach
runs-on: ubuntu-latest
env:
working-directory: ./sequential
steps:
- uses: actions/checkout@v3
- name: setup python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: install dependencies
working-directory: ${{ env.working-directory }}
run: pip install -r requirements.txt
- name: test main.py
working-directory: ${{ env.working-directory }}
run: pytest
run_graph:
name: testing graph approach
runs-on: ubuntu-latest
env:
working-directory: ./graph
steps:
- uses: actions/checkout@v3
- name: setup python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: install dependencies
working-directory: ${{ env.working-directory }}
run: pip install -r requirements.txt
- name: test main.py
working-directory: ${{ env.working-directory }}
run: pytest

💥 문제2 - data.csv 파일이 없습니다?
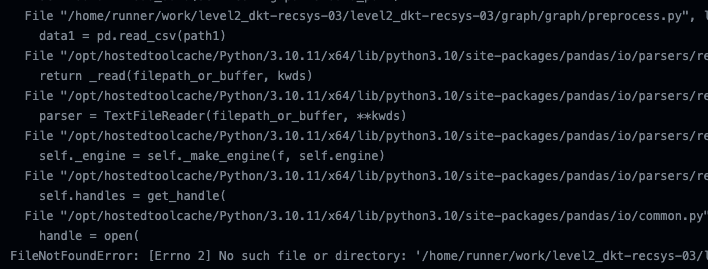
아참! 우리 팀의 github repository에는 data.csv파일이 없다! (당연한 것)
그렇다고 무턱대로 올릴 수도 없는 노릇인데...
고민을 좀 했다.
📝 wget을 쓰면 되잖아~
한동안 안되는줄 알고 아예 이슈를 덮어두었다.
그런데 생각을 해보니 우리 데이터 셋은 i-screen 데이터 셋으로 저작권 표시를 하면 사용이 가능하다.
바로 wget을 이용해 데이터를 넣어주기로 했다.
workflow 파일에서 각 job에 아래와 같은 step을 달아주었다.
- name: download dataset # Iscream-Edu dataset / CC-BY 2.0
run: |
wget https://aistages-prod-server-public.s3.amazonaws.com/app/Competitions/000240/data/data.tar.gz
mkdir -p ~/input/data
tar -zxvf data.tar.gz -C ~/input
🚀 모든 모델에 대해서 테스트
*이번 목차는 설명을 잘 못하겠습니다.. 바로바로 회고하지 않은 탓인것 같은데.. 읽는분들께 사과의 말씀드립니다.
우리 팀 프로젝트는 아래와 같이 config 파일을 계층적으로 구성했다. (hydra 사용)
configs
- data
- model
- paths
- trainer
- wandb
model폴더 안에는 여러 모델의 parameter 정보가 들어있는 식이다.
아무튼 그래서 이 모델들을 모두 테스트하고 싶어졌다. (기본 설정은 LGBM인데 매번 이것만 할 순 없지 않은가?)
그래서 일단 test.yaml을 만들고 이 설정파일을 main함수의 config인자로 집어 넣을것이다.
그러기 위해선 일단 아래 main함수에 붙은 @hydra.main을 떼어낼 필요가 있다.
...
# 이 아래 친구;; 이렇게 하면 테스트가 아닌 기본설정이 된다.
@hydra.main(version_base="1.2", config_path="configs", config_name="config.yaml")
def main(config: DictConfig = None) -> None:
<로직>
if __name__ == "__main__":
main()
이렇게 중요 로직과 hydra의 config주입을 분리했다.
...
def __main(config: DictConfig = None) -> None:
<여기에 로직이 들어감>
@hydra.main(version_base="1.2", config_path="configs", config_name="config.yaml")
def main(config: DictConfig = None) -> None:
__main(config)
if __name__ == "__main__":
main()
이후 test 파이썬 파일은 아래와 같이 구성했다.
...
@patch("wandb.init")
@patch("wandb.login")
@patch("wandb.log")
@patch("wandb.finish")
@patch("wandb.save")
@patch("pytorch_lightning.loggers.wandb.Run", new=Mock)
@patch("pytorch_lightning.loggers.wandb.wandb")
def test_main(*args, **kwargs):
@hydra.main(version_base="1.2", config_path="configs", config_name="test.yaml")
def inner_main(config: DictConfig) -> None:
# 모든 model을 하나씩 테스트함
for model_path in os.listdir("configs/model.test"):
model_path = os.path.join("configs/model.test", model_path)
model_config = omegaconf.OmegaConf.load(model_path)
config.model = model_config
__main(config)
inner_main()
💥 문제 3 - 너무 느린 테스트
테스트는 이제 원활하게 되지만, 테스트가 너무 느렸다.
이렇게 느리니 팀원들의 작업속도를 높이고자 했던 깃헙엑션이 오히려 발목을 잡고있었다.

게다가 우리는 브랜치당 개발 속도가 길어야 2일로 매우 빨랐기 때문에 10분은 엄청 큰 시간으로 느껴졌다.

📝 더미데이터
그래서 이걸 바꾸고자 했다.
일단 가장 먼저 손을 댄 곳은 데이터 부분이다.
원본 데이터보다 작은 더미데이터를 만들어 테스트에 쓰는 것!
우리 데이터 파일은 train_data.csv, valid_data.csv, test_data.csv가 있는데, 이걸 각각 1000, 100, 1000개의 row로 확 줄여버렸다.
속도는 얼마나 향상 되었을까?
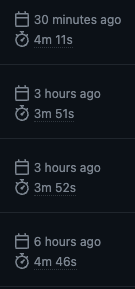
무려 4분 으로 줄어들었다.
📝 pip caching
이번엔 python module들을 캐싱을 통해 빠른 모듈 설치를 유도했다.
간단히 아래의 스탭을 추가해주면 된다.
- uses: actions/cache@v2
with:
path: ${{ env.pythonLocation }}
key: ${{ env.pythonLocation }}-tab-${{ hashFiles('setup.py') }}-${{ hashFiles('requirements.txt') }}그래서 결과는? 3분이 되었다!

💥 문제 4 - 캐싱이 안되잖아?
캐싱이 잘 될거라고 생각하고 있었는데... 알고보니 캐싱된 모듈을 찾지 못하는 일이 벌어지고 있었다.
캐싱 key가 다른가? 싶어서 캐시된 값을 보았는데, 아래와 같이 중복되어서 캐시를 만드는 일이 벌어지고 있었다.
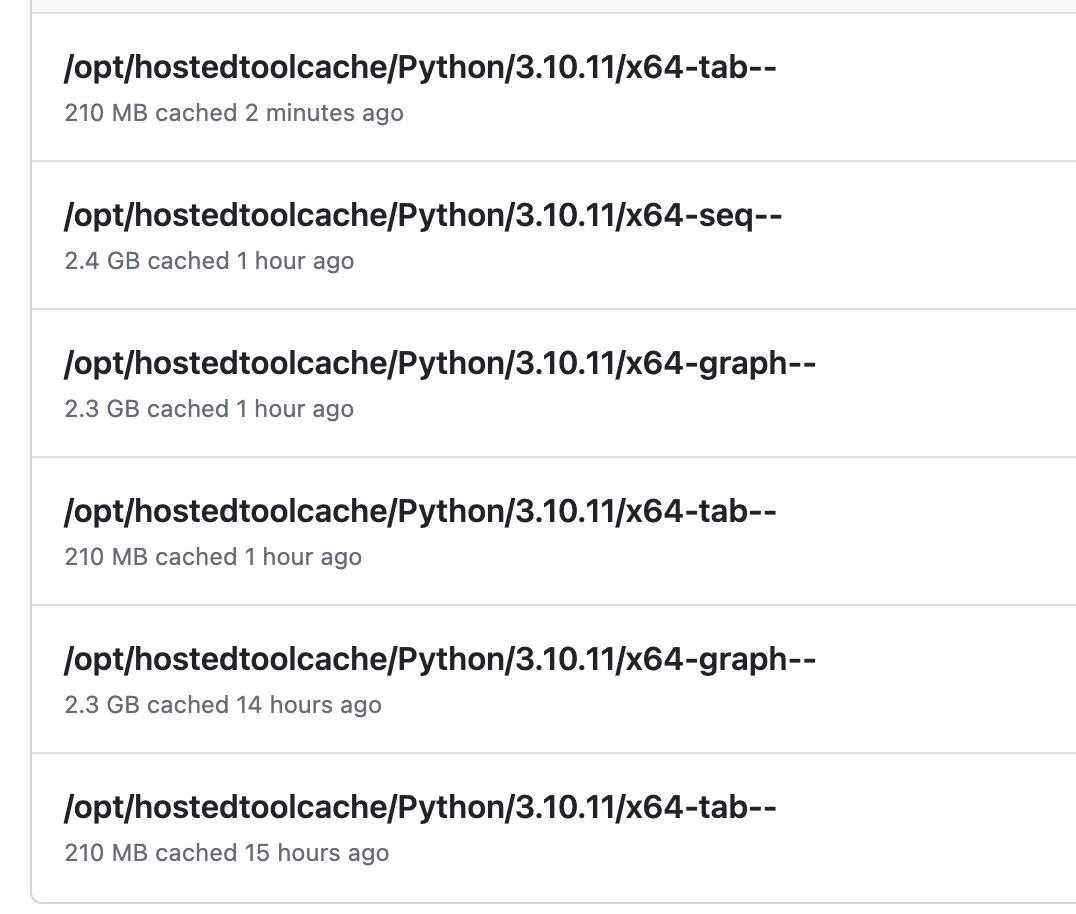
https://github.com/orgs/community/discussions/27059
구글링을 좀 해보니 기본 브랜치가 아닌 곳에서 캐싱을 하면
그 캐시값은 그 브랜치밖에 사용을 못한다고 한다.
Actions/cache: Cache not being hit despite of being present · community · Discussion #27059
Hi, My workflow looks like this: - name: Set Poetry Config run: | poetry config virtualenvs.create true poetry config cache-dir - uses: actions/cache@v1 name: Poetry Cache with: path: ~/.cache/pypo...
github.com
때문에 main에 캐시를 만들기 위해 main에 push할때도 캐시를 만들게 했다. (정확하게는 그냥 같은 워크플로우를 돌렸다.)
아래처럼 yaml파일을 수정했다.
on:
pull_request:
branches: [main]
push:
branches: [main]💬 마무리
이번 기회를 통해서 저번에 못했던 테스트를 추가해볼 수 있었고 깃헙 엑션까지 응용해볼 수 있었다.
또한, 캐싱과 더미데이터를 통해 빠른 테스트가 가능하게 했다.
'프로그래밍 > 부스트캠프 AI' 카테고리의 다른 글
| [Imgenie] 회고 (0) | 2023.08.28 |
|---|---|
| [Movie Rec] S3Rec의 모듈화 시도 (0) | 2023.06.25 |
| [DKT] lgbm에 label을 feature로 넣으면... (0) | 2023.05.12 |
| DKT - EDA 해보기 (1) | 2023.05.06 |
| [level1] preprocess 최적화 (캐싱) (0) | 2023.04.16 |
🤔 발단
이전 프로젝트(Book recommendation) 때부터 자동화된 테스트를 도입하고 싶었다.
그래서 이전에도 사용해본 적 있는 "Github Action"을 꼭 써보고 싶었는데, 이번에 여러 문제를 겪으며 적용해보았다.
💥 문제1 - wandb logger
우리는 지금 당장은 통합테스트를 수행할 것이다.
그리고 Github Action을 이용할 것이기 때문에 API KEY가 필요한 것은 배제해야 한다.
-> 그것이 이번 문제의 주인공인 wandb가 되겠다.
📝 @patch
모킹은 좋은 방법이 아니지만, 어쩔 수 없이 써야 할 때가 있기 마련이다.
파이썬은 그래서 @patch라는 모킹 데코레이터 함수를 제공해주고 있다.
@patch(패키지.함수) 와 같은 형태로 테스트 함수에 달아주면 된다.
아무튼 아래와 같이 test code를 작성했다.
main은 프로그램 시작점이고, wandb.init, wandb.login 등의 함수가 호출되면 아무일도 일어나지 않게 될것이다.
+ 추가로 pytorch lightning logger에서도 wandb를 사용하기 때문에 이것도 모킹을 해줘야 한다.
from unittest.mock import patch, Mock
from main import main
@patch('wandb.init')
@patch('wandb.login')
@patch('wandb.log')
@patch('wandb.finish')
@patch('wandb.save')
@patch("pytorch_lightning.loggers.wandb.Run", new=Mock)
@patch("pytorch_lightning.loggers.wandb.wandb")
def test_main(*args, **kwargs):
main()
📝 Github Action
그리고 이제 github action의 workflow에 관한 설정파일을 작성해야 한다.
그러기 전에 먼저 짚고 넘어가자.
우리 팀의 프로젝트는 아래와 같이 tabular, sequential, graph approach로 구분해 별개의 프로젝트를 담고 있다.
때문에 별개로 가상환경도 설치해줘야 한다. (우리팀은 conda로 관리중)
이러한 점은 job을 이용해 병렬로 각 어프로치 프로젝트의 테스트가 병렬로 돌아갈 수 있게 했다.
workflow yaml은 우리 팀원분이 아래와 같이 작성해 주셨다. (tabular는 아직 작성하지 않았다)
name: check bug before merge
on:
pull_request:
branches: [main]
jobs:
run_seq:
name: testing sequential approach
runs-on: ubuntu-latest
env:
working-directory: ./sequential
steps:
- uses: actions/checkout@v3
- name: setup python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: install dependencies
working-directory: ${{ env.working-directory }}
run: pip install -r requirements.txt
- name: test main.py
working-directory: ${{ env.working-directory }}
run: pytest
run_graph:
name: testing graph approach
runs-on: ubuntu-latest
env:
working-directory: ./graph
steps:
- uses: actions/checkout@v3
- name: setup python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: install dependencies
working-directory: ${{ env.working-directory }}
run: pip install -r requirements.txt
- name: test main.py
working-directory: ${{ env.working-directory }}
run: pytest
💥 문제2 - data.csv 파일이 없습니다?
아참! 우리 팀의 github repository에는 data.csv파일이 없다! (당연한 것)
그렇다고 무턱대로 올릴 수도 없는 노릇인데...
고민을 좀 했다.
📝 wget을 쓰면 되잖아~
한동안 안되는줄 알고 아예 이슈를 덮어두었다.
그런데 생각을 해보니 우리 데이터 셋은 i-screen 데이터 셋으로 저작권 표시를 하면 사용이 가능하다.
바로 wget을 이용해 데이터를 넣어주기로 했다.
workflow 파일에서 각 job에 아래와 같은 step을 달아주었다.
- name: download dataset # Iscream-Edu dataset / CC-BY 2.0
run: |
wget https://aistages-prod-server-public.s3.amazonaws.com/app/Competitions/000240/data/data.tar.gz
mkdir -p ~/input/data
tar -zxvf data.tar.gz -C ~/input
🚀 모든 모델에 대해서 테스트
*이번 목차는 설명을 잘 못하겠습니다.. 바로바로 회고하지 않은 탓인것 같은데.. 읽는분들께 사과의 말씀드립니다.
우리 팀 프로젝트는 아래와 같이 config 파일을 계층적으로 구성했다. (hydra 사용)
configs
- data
- model
- paths
- trainer
- wandb
model폴더 안에는 여러 모델의 parameter 정보가 들어있는 식이다.
아무튼 그래서 이 모델들을 모두 테스트하고 싶어졌다. (기본 설정은 LGBM인데 매번 이것만 할 순 없지 않은가?)
그래서 일단 test.yaml을 만들고 이 설정파일을 main함수의 config인자로 집어 넣을것이다.
그러기 위해선 일단 아래 main함수에 붙은 @hydra.main을 떼어낼 필요가 있다.
...
# 이 아래 친구;; 이렇게 하면 테스트가 아닌 기본설정이 된다.
@hydra.main(version_base="1.2", config_path="configs", config_name="config.yaml")
def main(config: DictConfig = None) -> None:
<로직>
if __name__ == "__main__":
main()
이렇게 중요 로직과 hydra의 config주입을 분리했다.
...
def __main(config: DictConfig = None) -> None:
<여기에 로직이 들어감>
@hydra.main(version_base="1.2", config_path="configs", config_name="config.yaml")
def main(config: DictConfig = None) -> None:
__main(config)
if __name__ == "__main__":
main()
이후 test 파이썬 파일은 아래와 같이 구성했다.
...
@patch("wandb.init")
@patch("wandb.login")
@patch("wandb.log")
@patch("wandb.finish")
@patch("wandb.save")
@patch("pytorch_lightning.loggers.wandb.Run", new=Mock)
@patch("pytorch_lightning.loggers.wandb.wandb")
def test_main(*args, **kwargs):
@hydra.main(version_base="1.2", config_path="configs", config_name="test.yaml")
def inner_main(config: DictConfig) -> None:
# 모든 model을 하나씩 테스트함
for model_path in os.listdir("configs/model.test"):
model_path = os.path.join("configs/model.test", model_path)
model_config = omegaconf.OmegaConf.load(model_path)
config.model = model_config
__main(config)
inner_main()
💥 문제 3 - 너무 느린 테스트
테스트는 이제 원활하게 되지만, 테스트가 너무 느렸다.
이렇게 느리니 팀원들의 작업속도를 높이고자 했던 깃헙엑션이 오히려 발목을 잡고있었다.
게다가 우리는 브랜치당 개발 속도가 길어야 2일로 매우 빨랐기 때문에 10분은 엄청 큰 시간으로 느껴졌다.
📝 더미데이터
그래서 이걸 바꾸고자 했다.
일단 가장 먼저 손을 댄 곳은 데이터 부분이다.
원본 데이터보다 작은 더미데이터를 만들어 테스트에 쓰는 것!
우리 데이터 파일은 train_data.csv, valid_data.csv, test_data.csv가 있는데, 이걸 각각 1000, 100, 1000개의 row로 확 줄여버렸다.
속도는 얼마나 향상 되었을까?
무려 4분 으로 줄어들었다.
📝 pip caching
이번엔 python module들을 캐싱을 통해 빠른 모듈 설치를 유도했다.
간단히 아래의 스탭을 추가해주면 된다.
- uses: actions/cache@v2
with:
path: ${{ env.pythonLocation }}
key: ${{ env.pythonLocation }}-tab-${{ hashFiles('setup.py') }}-${{ hashFiles('requirements.txt') }}그래서 결과는? 3분이 되었다!
💥 문제 4 - 캐싱이 안되잖아?
캐싱이 잘 될거라고 생각하고 있었는데... 알고보니 캐싱된 모듈을 찾지 못하는 일이 벌어지고 있었다.
캐싱 key가 다른가? 싶어서 캐시된 값을 보았는데, 아래와 같이 중복되어서 캐시를 만드는 일이 벌어지고 있었다.
https://github.com/orgs/community/discussions/27059
구글링을 좀 해보니 기본 브랜치가 아닌 곳에서 캐싱을 하면
그 캐시값은 그 브랜치밖에 사용을 못한다고 한다.
Actions/cache: Cache not being hit despite of being present · community · Discussion #27059
Hi, My workflow looks like this: - name: Set Poetry Config run: | poetry config virtualenvs.create true poetry config cache-dir - uses: actions/cache@v1 name: Poetry Cache with: path: ~/.cache/pypo...
github.com
때문에 main에 캐시를 만들기 위해 main에 push할때도 캐시를 만들게 했다. (정확하게는 그냥 같은 워크플로우를 돌렸다.)
아래처럼 yaml파일을 수정했다.
on:
pull_request:
branches: [main]
push:
branches: [main]💬 마무리
이번 기회를 통해서 저번에 못했던 테스트를 추가해볼 수 있었고 깃헙 엑션까지 응용해볼 수 있었다.
또한, 캐싱과 더미데이터를 통해 빠른 테스트가 가능하게 했다.
'프로그래밍 > 부스트캠프 AI' 카테고리의 다른 글
| [Imgenie] 회고 (0) | 2023.08.28 |
|---|---|
| [Movie Rec] S3Rec의 모듈화 시도 (0) | 2023.06.25 |
| [DKT] lgbm에 label을 feature로 넣으면... (0) | 2023.05.12 |
| DKT - EDA 해보기 (1) | 2023.05.06 |
| [level1] preprocess 최적화 (캐싱) (0) | 2023.04.16 |